Data
Structure:
A data structure is a particular way of storing and
organizing data in a computer so that it can be used efficiently. Data
structures provide a means to manage large amounts of data efficiently.
efficient data structures are a key to designing efficient algorithms.
List of Data Structures
· Stacks
· Queues
· Linked
List
Stack:

A Stack is an abstract data type or
collection where in Push,the addition of data elements to the collection, and
Pop, the removal of data elements from the collection, are the major operations
performed on the collection. The Push and Pop operations are performed only at
one end of the Stack which is referred to as the 'top of the stack'.
In other words,a Stack can be simply
defined as Last In First Out (LIFO) data structure,i.e.,the last element added
at the top of the stack(In) should be the first element to be removed(Out) from
the stack.
Stack Operations:
Push: A new entity can be added to the top
of the collection.
Pop: An entity will be removed from the top of the collection.
Peek or Top: Returns the top of the entity without removing it.
Pop: An entity will be removed from the top of the collection.
Peek or Top: Returns the top of the entity without removing it.
Overflow State: A stack may be implemented to have a
bounded capacity. If the stack is full and does not contain enough space to
accept an entity to be pushed, the stack is then considered to be in an
overflow state.
Underflow State: The pop operation removes an item from
the top of the stack. A pop either reveals previously concealed items or
results in an empty stack, but, if the stack is empty, it goes into underflow
state, which means no items are present in stack to be removed.
A stack is a restricted data
structure, because only a small number of operations are performed on it. The
nature of the pop and push operations also means that stack elements have a
natural order. Elements are removed from the stack in the reverse order to the
order of their addition. Therefore, the lower elements are those that have been
on the stack the longest.
Efficiency of Stacks
In the stack, the elements can be push
or pop one at a time in constant O(1) time. That is, the time is not dependent
on how many items are in the stack and is therefore very quick. No comparisons
or moves are necessary.
Queue:

A queue is a kind of abstract data
type or collection in which the entities in the collection are kept in order
and the only operations on the collection are the addition of entities to the
rear terminal position, called as enqueue, and removal of entities from the
front terminal position, called as dequeue. The queue is called as
First-In-First-Out (FIFO) data structure. In a FIFO data structure, the first
element added to the queue will be the first one to be removed. This is
equivalent to the requirement that once a new element is added, all elements
that were added before have to be removed before the new element can be
removed. Often a peek or front operation is also entered, returning the value
of the front element without dequeuing it. A queue is an example of a linear
data structure, or more abstractly a sequential collection.
Queues provide services in computer
science, transport, and operations research where various entities such as
data, objects, persons, or events are stored and held to be processed later. In
these contexts, the queue performs the function of a buffer.
Queue Operations:
enqueue: Adds an item onto the end of the
queue.
front: Returns the item at the front of the queue.
dequeue: Removes the item from the front of the queue.
front: Returns the item at the front of the queue.
dequeue: Removes the item from the front of the queue.
Overflow State: A queue may be implemented to have a
bounded capacity. If the queue is full and does not contain enough space to
accept an entity to be pushed, the queue is then considered to be in an
overflow state.
Underflow State: The dequeue operation removes an item
from the top of the queue. A dequeue operation either reveals previously
concealed items or results in an empty queue, but, if the queue is empty, it
goes into underflow state, which means no items are present in queue to be
removed.
Efficiency of Queue
The time needed to add or delete an
item is constant and independent of the number of items in the queue. So both
addition and deletion can be O(1) operation.
Deque:
A double-ended queue (dequeue or
deque) is an abstract data type that generalizes a queue, for which elements
can be added to or removed from either the front or rear. Deque differs from
the queue abstract data type or First-In-First-Out List (FIFO), where elements
can only be added to one end and removed from the other. This general data
class has some possible sub-types:
1) An input-restricted deque is one
where deletion can be made from both ends, but insertion can be made at one end
only.
2) An output-restricted deque is one where insertion can be made at both ends, but deletion can be made from one end only.
2) An output-restricted deque is one where insertion can be made at both ends, but deletion can be made from one end only.

You can use Deque as a stack by making
insertion and deletion at the same side. Also you can use Deque as queue by
making insetting elements at one end and removing elements at other end.
The common way of deque
implementations are by using dynamic array or doubly linked list. Here this
example shows the basic implementation of deque using a list, which is
basically a dynamic array.
The complexity of Deque operations is
O(1), when we not consider overhead of allocation/deallocation of dynamic array
size.
Priority
Queue:
A priority queue is an abstract data
type, it is like a regular queue or stack data structure, but where
additionally each element has a priority associated with it. In a priority
queue, an element with high priority is served before an element with low
priority. If two elements have the same priority, they are served according to
their order in the queue.
There are a variety of simple ways to
implement a priority queue. For instance, one can keep all the elements in an
unsorted list. Whenever the highest-priority element is requested, search
through all elements for the one with the highest priority. In big O notation:
O(1) insertion time, O(n) pull time due to search.
Linked
List:
A linked list is a data structure
consisting of a group of nodes which together represent a sequence. Each node
is composed of a data and a link or reference to the next node in the sequence.
This structure allows for efficient insertion or removal of elements from any position
in the sequence.The last node is linked to a terminator used to signify the end
of the list.

Linked lists are the simplest and most
common data structures. They can be used to implement several other abstract
data types, including lists, stacks, queues, associative arrays, and
S-expressions, etc.
The benefits of a linked list over a
conventional array is that the linked list elements can easily be inserted or
removed without reallocation or reorganization of the entire structure because
the data items need not be stored contiguously in memory or on disk. Linked
lists allow insertion and removal of nodes at any point in the list.
On the other hand, simple linked lists
do not allow random access to the data, or by using indexing. Thus, many basic
operations like obtaining the last node of the list, or finding a node with
required data, or locating the place where a new node should be inserted, may
require scanning most of the list elements.
Single
Linked List:
Singly Linked Lists are a type of data
structure. It is a type of list. In a singly linked list each node in the list
stores the contents of the node and a pointer or reference to the next node in
the list. It does not store any pointer or reference to the previous node. It
is called a singly linked list because each node only has a single link to
another node. To store a single linked list, you only need to store a reference
or pointer to the first node in that list. The last node has a pointer to
nothingness to indicate that it is the last node.
Here is the pictorial view of singly
linked list:
Here is
the pictorial view of inserting an element in the middle of a singly linked
list:
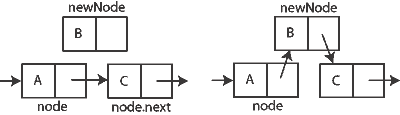
Here is the pictorial view of deleting
an element in the middle of a singly linked list:

Double
Linked List:
A doubly-linked list is a linked data
structure that consists of a set of sequentially linked records called nodes.
Each node contains two fields, called links, that are references to the
previous and to the next node in the sequence of nodes. The beginning and
ending nodes previous and next links, respectively, point to some kind of
terminator, typically a sentinel node or null, to facilitate traversal of the
list. If there is only one sentinel node, then the list is circularly linked
via the sentinel node. It can be conceptualized as two singly linked lists
formed from the same data items, but in opposite sequential orders.
Here is the pictorial view of doubly
linked list:
The two node links allow traversal of
the list in either direction. While adding or removing a node in a
doubly-linked list requires changing more links than the same operations on a
singly linked list, the operations are simpler and potentially more efficient,
because there is no need to keep track of the previous node during traversal or
no need to traverse the list to find the previous node, so that its link can be
modified.
Here is the pictorial view of
inserting an element in the middle of a doubly linked list:

Here is the pictorial view of deleting
an element in the middle of a doubly linked list:

No comments:
Post a Comment